Tuning PostgreSQL to reduce SSD wearout
Recently I tried to find an article with a title like this, but found nothing. So, here it is.
Solid-state drives wear out from writes. Manufactures even put the amount of writes in their warranty conditions. For example, my 1TB "Samsung 870 EVO" marked as "5 years or 600 TB of writes — whatever comes first".
These are results of my experiments of reducing writes of @rss2tg_bot by postgresql.conf tuning. These charts are kinda spiky to estimate, but that's about 50% reduce in bytes per day:
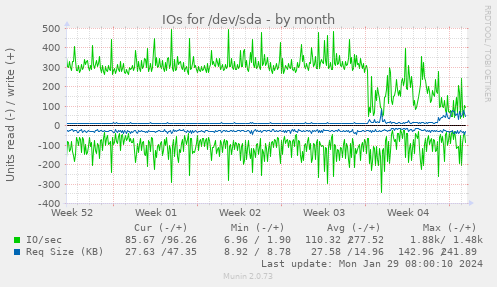
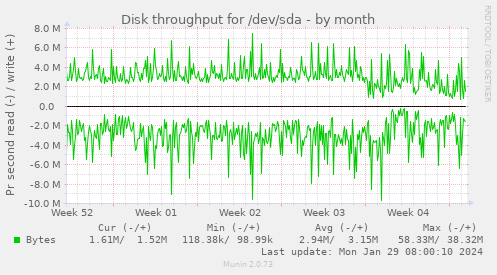
Of course, the best way to reduce writes is to do less of INSERTs or UPDATEs, and also reduce the "width" of your tables. Remember, each time when you UPDATE a single column, the new version of the entire row has to be written. This is how MVCC in PostgreSQL works, and this is inevitable. But that's not the subject of this article.
When should you bother
-
When your disk has a significant write load
You can runiostatto estimate. It outputs stats since the machine boot. TakekB_wrtn/s× 60 × 60 × 24 × 365 ÷ 1024 ÷ 1024 ÷ 1024 — and you'll estimate a number of terabytes per year.- @rss2tg_bot produces something like 80 TB of writes per year.
-
When you have tables changing, not only appending
When youUPDATEa lot, orINSERTafterDELETE.- @rss2tg_bot works exactly that way. New feeds arrive, old feeds recycle.
-
When your tables are comparable by size with the amount of free memory
The only effective way to reduce disk writes is to allow data to stuck in memory buffers for a longer time. This wouldn't work if you have too much of data and too little of memory.- @rss2tg_bot operates a database of 80GB, with the biggest table of 32GB, while having 26GB of memory free for caches.
Tuning trick 1: asynchronous commits
- In
postgresql.conf:synchronous_commit = off - Impact on writes: reduces a little
- Impact on performance: increases a lot
- ⚠ This setting will reduce the reliability of your database. In case of crash or poweroff you will loose transactions of the last few seconds, but the rest of the database will be fine.
Short explanation: it disables invoking fsync() for WAL on each COMMIT.
But what the hell are fsync() and WAL?
Here goes a long explanation.
When you ask your operating system to write something on disk, the OS wouldn't actually do it. Instead, your data will stuck for a some time in a memory cache, or "write buffer". So if you want to be sure your data will undergo system crash or poweroff, you want to use fsync() system call to ask the operating system to actually flush data on disk.
But PostgreSQL doesn't rely on fsync() to keep a database in a consistent state. Besides, PostgreSQL doesn't keep a database consistent at all. A database is a permanent mess of chunks of data written on disk and chunks of data stuck in memory. Instead, before writing into the database, PostgreSQL describes everything it's going to do in the Write-Ahead Log. With WAL, a database could be restored even after a crash. WAL is an append-only file, so it's impossible to corrupt it in a catastrophic way.
By default, PostgreSQL invokes fsync() on WAL on each transaction commit. By disabling it, last transactions appended to WAL could be lost in a case of a crash. But no flushing on disk also provides a better buffering, causing writes to disk to be in bigger chunks.
Tuning trick 1.5: increasing time between WAL flushes
- In
postgresql.conf:wal_writer_delay = 10s # default 200ms
wal_writer_flush_after = 8MB # default 1MB - This setting is useless without the previous one.
- Unfortunatelly I couldn't measure any real difference. But it should help!
Tuning trick 2: WAL compression
- In
postgresql.conf:wal_compression = on - Impact on writes: reduces a little
- Impact on performance: reduces a tiny bit
I bet you already understand what compression means.
Tuning trick 3: increasing time between checkpoints
- In
postgresql.conf:checkpoint_timeout = 3h # or bigger; default 5min
max_wal_size = 20GB # or bigger; default 1GB - Impact on writes: reduces a little
- Impact on performance: jiggling
- Impact on occupied space: +10GB
As I said before, a database is always in a state of a permanent mess. But there are moments when it is in a completely consistent state on the disk. These moments are called "checkpoints", and PostgreSQL do checkpoints in order to be able to remove old segments of write-ahead log.
Less checkpoints you made, more time your data could live in a write buffer.
By doing this you will also increase performance when checkpoints are not being invoked, but every checkpoint will cause a spike in latency. You will also increase the startup time of your database.
Tuning trick 4: killing background writer
- In
postgresql.conf:bgwriter_lru_maxpages = 0 - Impact on writes: reduces a lot
- Impact on performance: jiggling
Background writer, well, writes from cache to disk when the database has nothing to do. This is how it achieves steady performance.
In the case of SSD, this is the dumbest thing ever. Our disks are fast enough to flush all the buffers quickly, but this background writer produces a lot of writes we don't want.
This setting works best with the increased checkpoint_timeout above.
Tuning trick 5: choosing one of two buffering strategies
Alsmost every setting above basically was aiming one goal: to keep data in a memory buffer as long as possible, so a data block could be changed multiple times before it actually being written on the disk.
The problem is: there are two layers of these memory buffers. The one is "shared buffers" of PostgreSQL (you might already heard about them), and the other one are buffers in you operating system (I hope it's Linux since that's everything I use). And you should choose one of them to rely on, because splitting your memory 50%/50% is the worst-case scenario: you can use only 50% of your memory as a cache!
Shared buffers strategy
This is the easies one. You just set shared_buffers to 80% of your free memory or something.
And I don't like it. The main reason is me usually having no servers dedicated only for a database. And I don't want nothing to be OOM killed.
Linux buffers strategy
I'll just show you how I set everyting up:
echo 360000 > /proc/sys/vm/dirty_expire_centisecs
echo 360000 > /proc/sys/vm/dirty_writeback_centisecs
echo 70 > /proc/sys/vm/dirty_background_ratio
echo 70 > /proc/sys/vm/dirty_ratio
That means: occupy up to 70% of free memory for buffers, flush them every hour.
The problem with all these settings is: despite the documentation, none of them makes any sense.
dirty_expire_centisecsdoesn't make any difference no matter what value was set. Maybe it's because files of a PostgreSQL database are too large, and there are always some expired slabs in them, but the system could flush only the whole file. I don't know.dirty_background_ratioworks in no dependence ofdirty_writeback_centisecs. I mean it's like "whatever comes first".
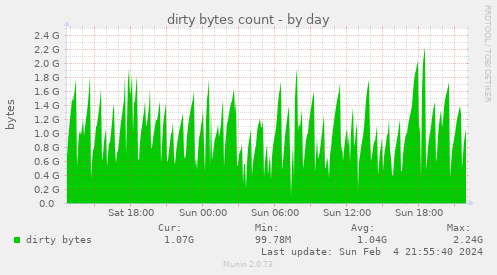
The good part is: you can monitor the current size of cached buffers via:grep Dirty /proc/meminfo
I even made a munin plugin for that:
By the way, stupid questions
Is it harmful to update a single row million times?
No. It makes zero difference where exactly you do writes on SSD. Even if you target a single block on disk, the internal controller will write the data in different physical blocks every time.
Moreover, on a physical level there is no such thing as "modifying row" in PostgreSQL. It's kind of "append-only" database with a VACUUM function.